M24 Statistik 1: Wintersemester 23/24
Vorlesung 13: Metaanalyse
Health and Medical University Potsdam
Beispiel
Wir interessieren uns für den Zusammenhang zwischen der Nutzung sozialer Medien und psychischer Gesundheit.
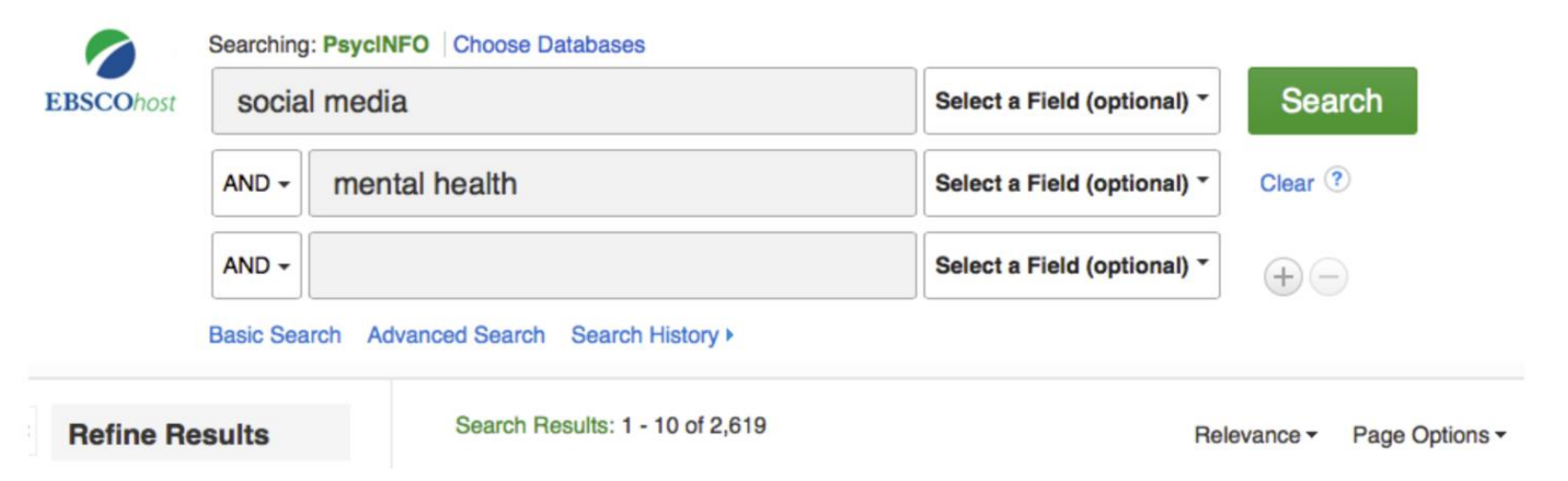
→ Für Details zur Literatursuche, siehe Vorlesung Forschungsmethoden.
Beispiel
Ein hypothetischer Beispielartikel aus der Literatursuche:

- Frage: wie kombinieren wir die Effekte vieler solcher Studien?
Metaanalyse – die Königsdisziplin

- Aber beachte: die Qualität von Reviews und Metaanalysen hängt von der Qualität der einzelnen Studien ab! So kann etwa eine große Metaanalyse auf Basis von verzerrten Studien eine geringere Evidenzqualität haben, als ein einzelner RCT (randomized controlled trial).
Was ist eine Metaanalyse?
- Generelle Idee: viele Studien sagen mehr als eine Einzelne
 |
Eine Metaanalyse kombiniert die berichteten Effekte verschiedener Studien mit dem Ziel eine genauere Schätzung eines Effektes zu berechnen. |
- Eine Metaanalyse kann auf unstandardisierten oder standardisierten Effekten basieren.
- Unstandardisierte Effekte:
- Relative/absolute Häufigkeiten
- Lagemaße
- Streuungsmaße
- Unterschiede
- Kovarianz, Regressionskoeffizient
- Standardisierte Effekte (aka Effektstärke):
- Cohen’s d
- Korrelation
Geschichte der Metaanalyse
- Stammt aus der Psychologischen Forschung
- Erste Metaanalyse von Hans Jürgen Eysenck (1952): Wirksamkeit der Psychoanalyse und anderer Therapieformen
- Begriff “Metaanalyse” eingeführt von Gene Glass:
“Meta-analysis refers to the analysis of analyses. I use it to refer to the statistical analysis of a large collection of analysis results from individual studies for the purpose of integrating the findings. It connotes a rigorous alternative to the casual narrative discussions of research studies which typify our attempts to make sense of the rapidly expanding research literature.”
Glass (1976)3


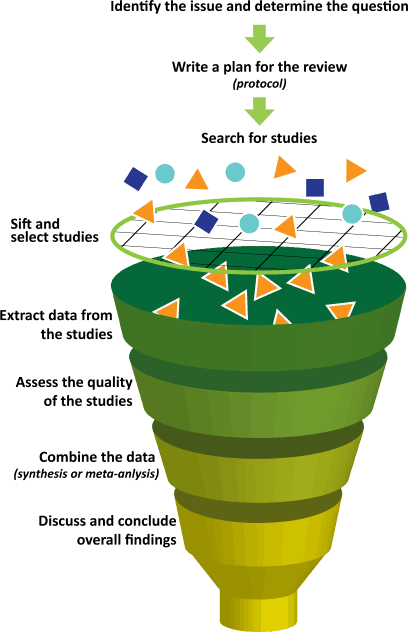
Vorgehen bei einer Metaanalyse
Für eine konkrete Fragestellung:
- Nach relevanten Forschungsarbeiten suchen (Datenbanken, Google, Bibliothek, Referenzen in Forschungsarbeiten…)
- Ein- und Ausschlusskriterien festlegen (z.B. Randomisierung, Kontrollgruppen, Ausschluss von Alternativerklärungen…)
- Auswahl relevanter Studien: Ein- und Ausschlusskriterien, genaue Fragestellung (dieselbe abhängige Variable?)
- Sich auf einen Kennwert einigen (z.B. \(r\))
- Für alle Studien die Ergebnisse in diesen Kennwert umrechnen, falls sie nicht schon so vorliegen
- Kennwerte mitteln (i.d.R. an der Stichprobengröße/Varianz gewichteter Mittelwert)
Vorgehen bei einer Metaanalyse
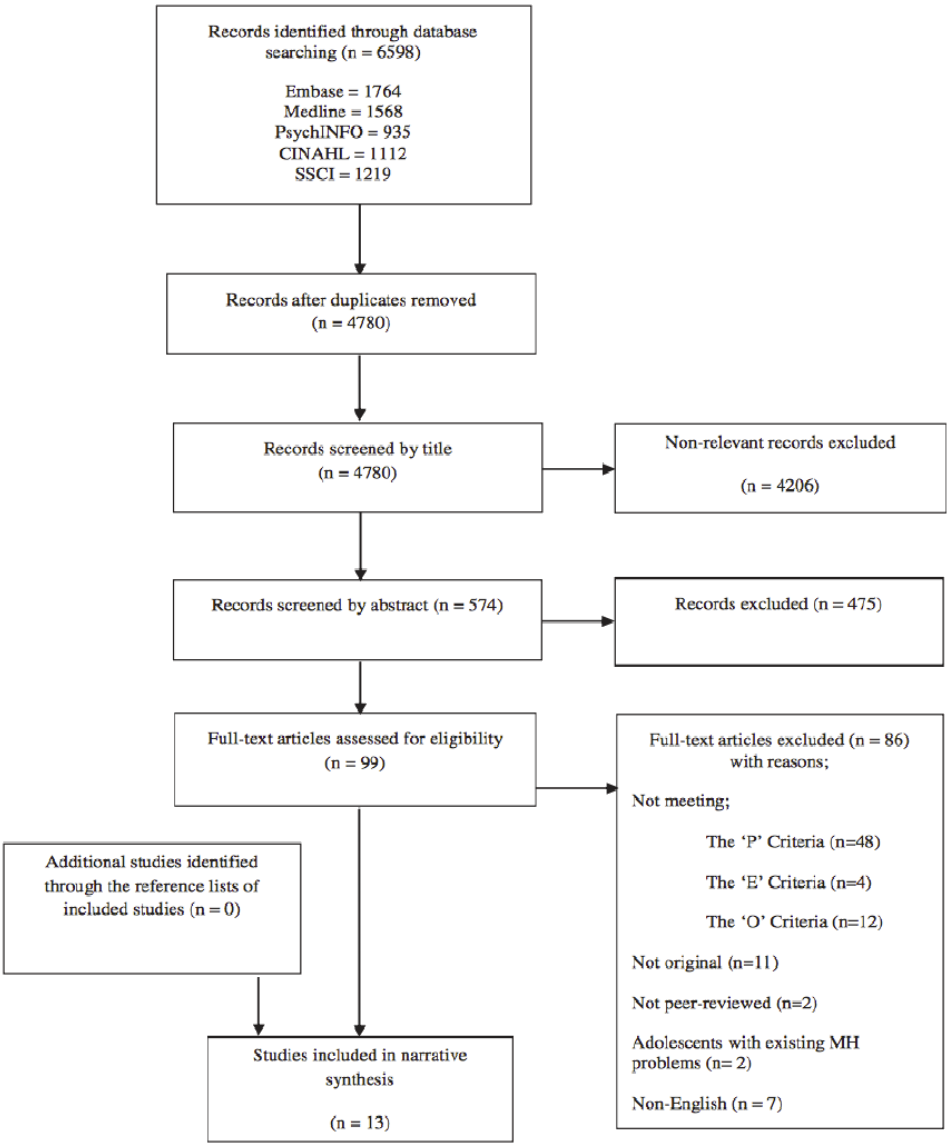
Die Suche und Auswahl der relevanten Studien sowie die Effekte der Ein- und Ausschlusskriterien werden in einem Flussdiagramm dargestellt.

Im Beispielflusdiagramm wird das PEO-Framework zur Auswahl relevanter Studien benutzt:
- Population (‘P’ Criteria)
Welche Population wird untersucht? Frauen, Studierende, Menschen mit spezifischer Diagnose, … - Exposure (‘E’ Criteria) — die unabhängige Variable
Welche Erkrankung weist die Population auf ODER welchem potentiellen Risikofaktor war die Population ausgesetzt ODER welcher Intervention / Treatment wurde die Population unterzogen? - Outcome (‘O’ criteria) — die abhängige Variable
Was wird gemessen? Wahrscheinlichkeit einer Erkrankung, Heilungsfortschritt, Lebensqualität, Einstellungen, usw.
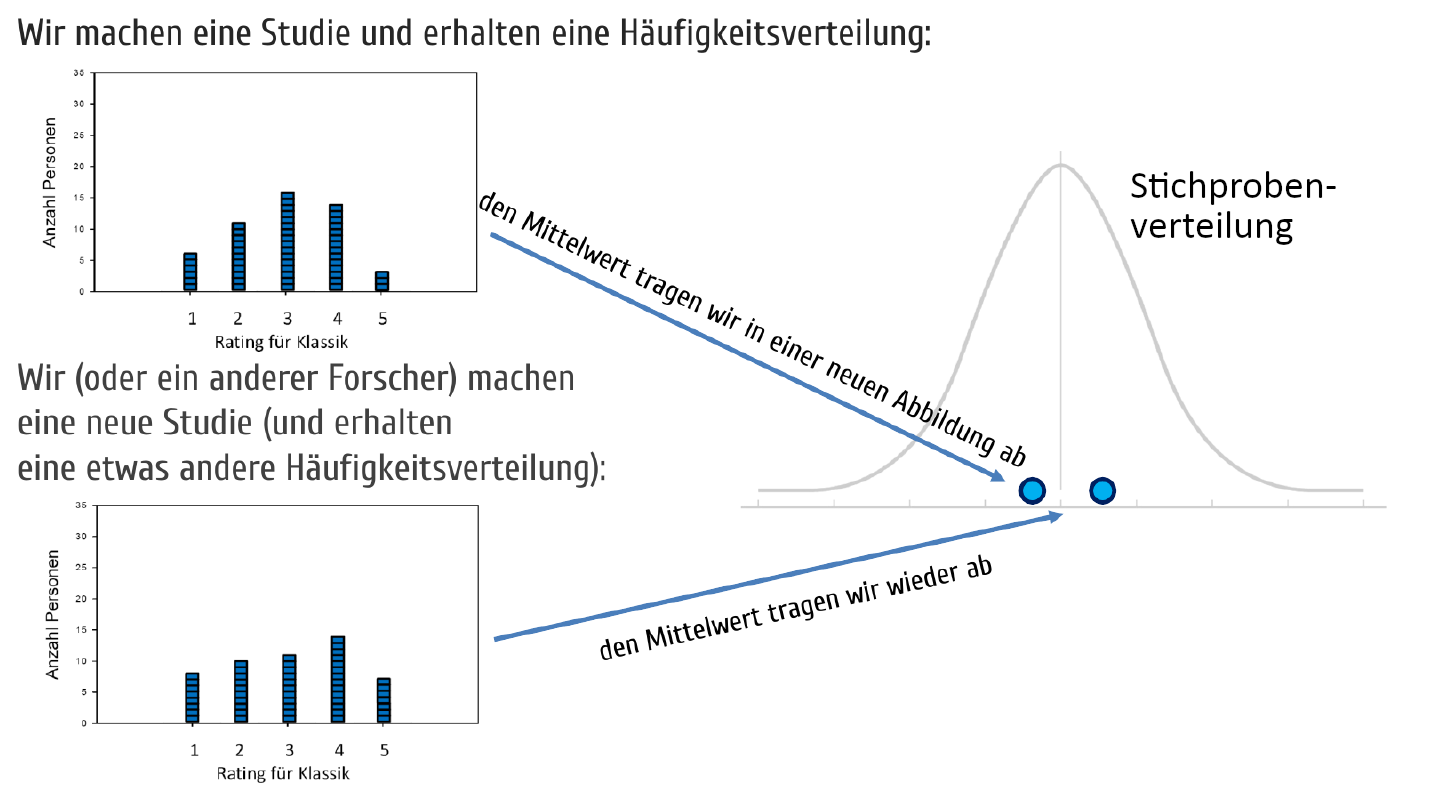
Vorgehen bei einer Metaanalyse
Beispiel am Mittelwert: die Mittelwerte verschiedener Studien bilden selbst wieder eine Verteilung — die empirische Stichprobenverteilung.
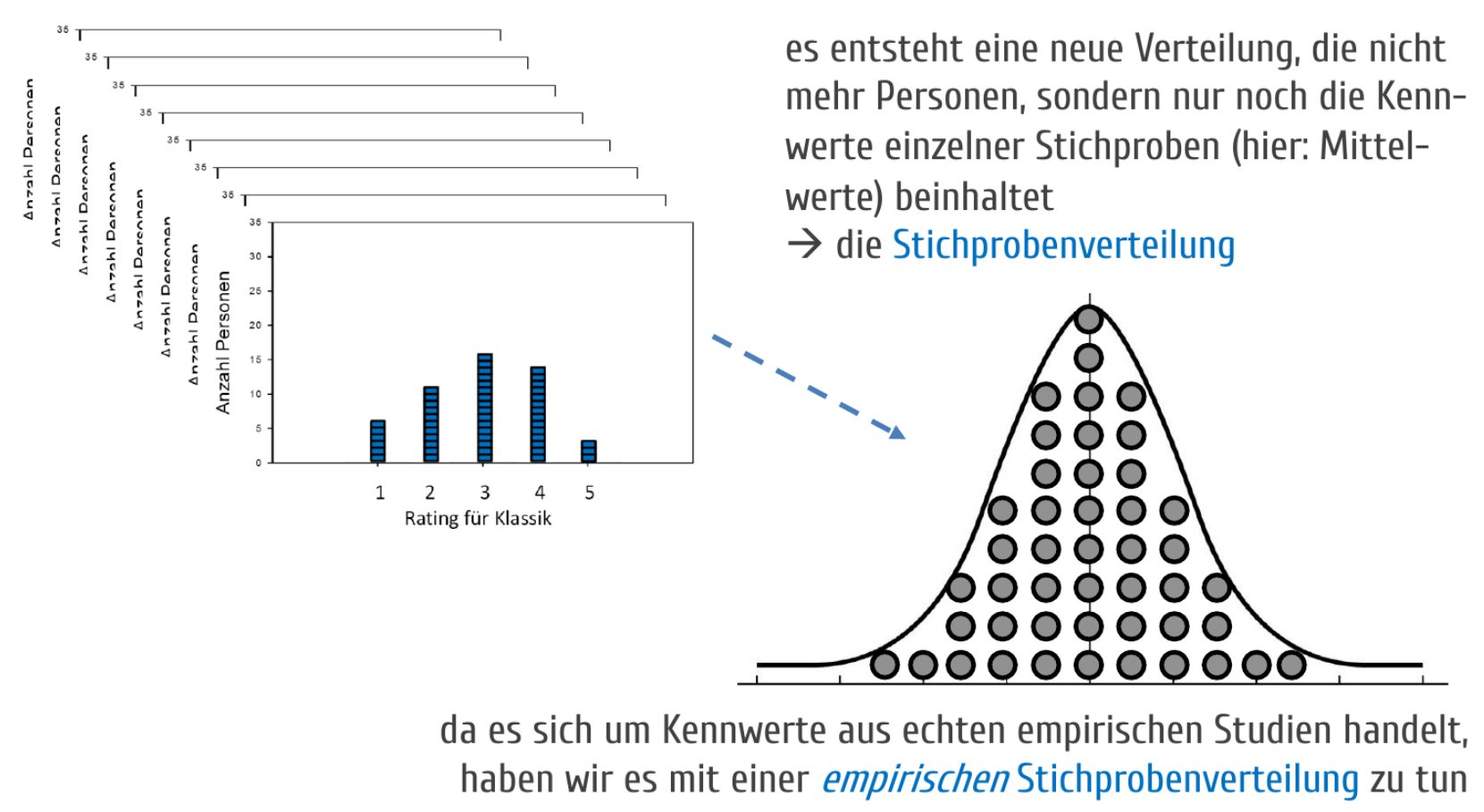
Vorgehen bei einer Metaanalyse
Beispiel am Mittelwert: die Mittelwerte verschiedener Studien bilden selbst wieder eine Verteilung — die empirische Stichprobenverteilung.
Inverse Samplingvarianz: Formeln

- Cohen’s d (unabhängige Messungen Gruppen A und B):
\[ v_i = \frac{n_A + n_B}{n_A n_B} + \frac{d^2}{2(n_A+n_C)} \]
\(n_A\)/\(n_B\) sind die Fallzahlen in den Gruppen A/B der Studie \(i\), \(d\) ist das Cohen’s \(d\) der Studie.
\[ v_i = \frac{d^2+2}{2n} \]
- Pearson-Korrelation (Annahme: z-transformierte Korrelationskoeffizienten — häufigster Fall!):
\[ v_i = \frac{1}{n-3} \]
- Pearson-Korrelation (Rohe Korrelationskoeffizienten):
\[ v_i = \frac{\left(1-r^2\right)^2}{n-1} \]
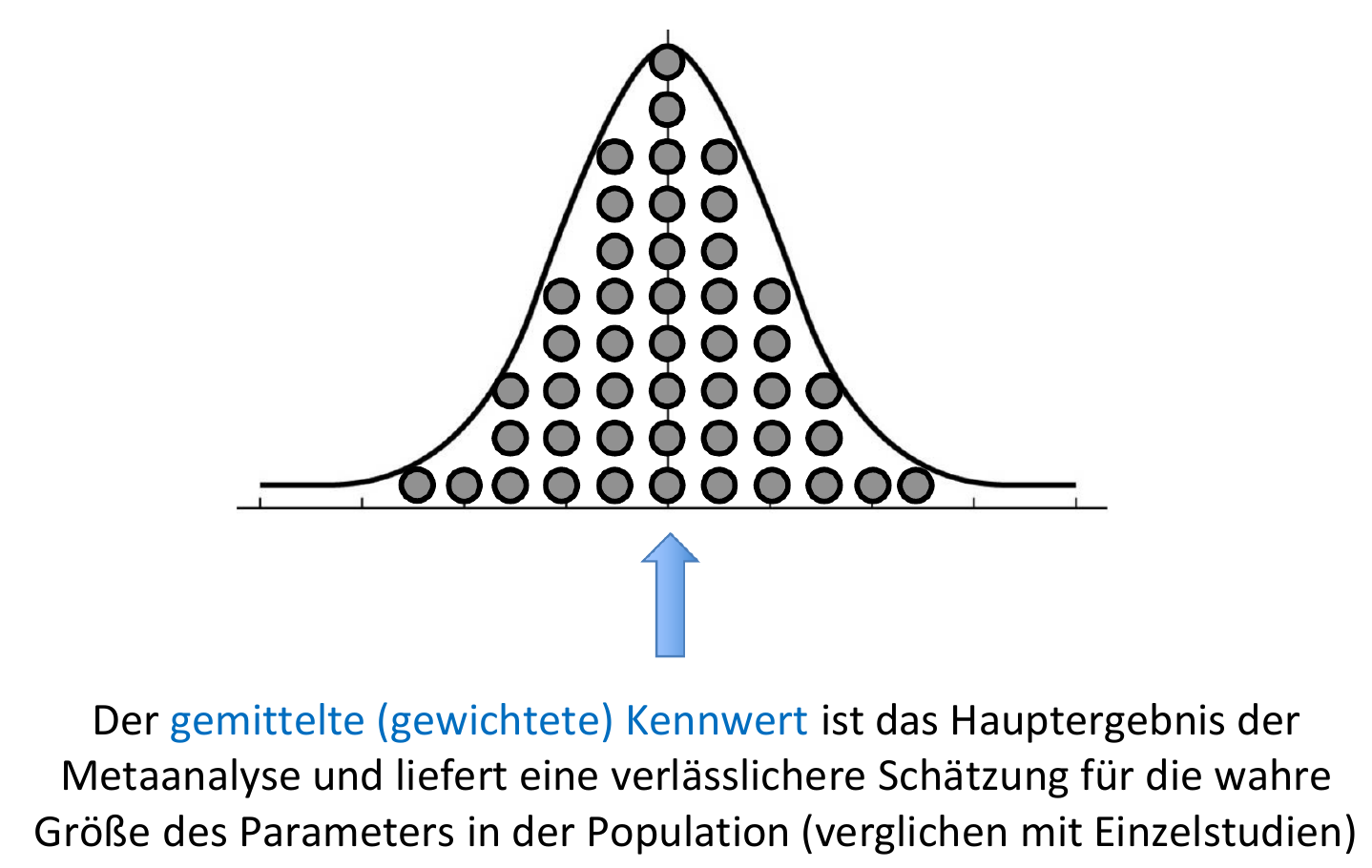
Ergebnis der Metaanalyse
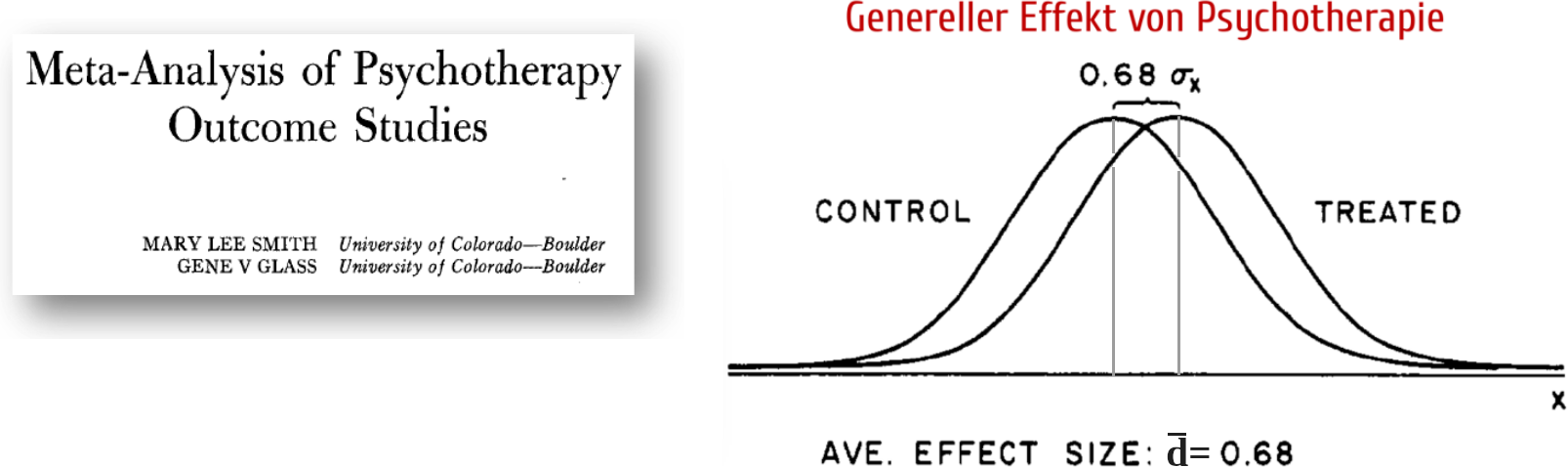
Beispiel 1: wirkt Psychotherapie?
- Metaanalyse von Smith und Glass (1977)7
- Verglichen wurde „Therapie vs. keine Therapie” für eine Reihe von psychischen Störungen (knapp 400 Studien insgesamt):
- Berechnet wurde schließlich ein mittleres d:
Beispiel 1: wirkt Psychotherapie?
- Metaanalyse von Smith und Glass (1977)8
- Moderatorvariable 1: unterscheidet sich die Wirksamkeit je nach Art der Therapie?
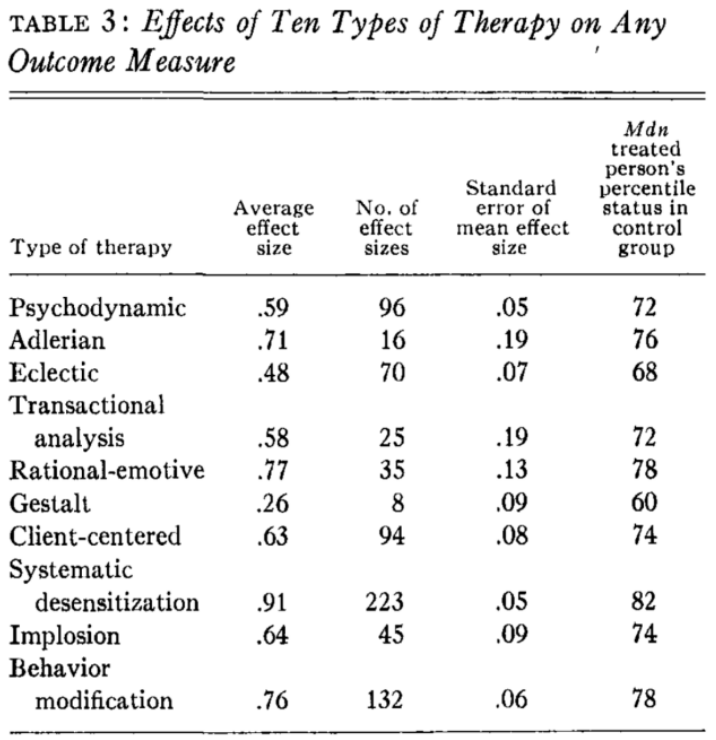
Nach dieser Metaanalyse weisen die unterschiedlichen Psychpotherapie-Schulen/Arten deutlich unterschiedliche Effektstärken auf: Spannbreite von Gestalttherapie \((d=0{,}26)\) bis Systematische Desensibilisierung (Expositionstherapie) \((d=0{,}91)\)
Ergebnis ist mit Vorsicht zu genießen: keine Information über die jeweils behandelten Erkrankungen; recht alte Studie, die Probleme wie Publikationsbias und Studienqualität nicht nach heutigen Maßstäben berücksichtigt.
Beispiel 1: wirkt Psychotherapie?
- Metaanalyse von Smith und Glass (1977)9
- Moderatorvariable 2: unterscheidet sich die Wirksamkeit je nach Outcome-Maß?
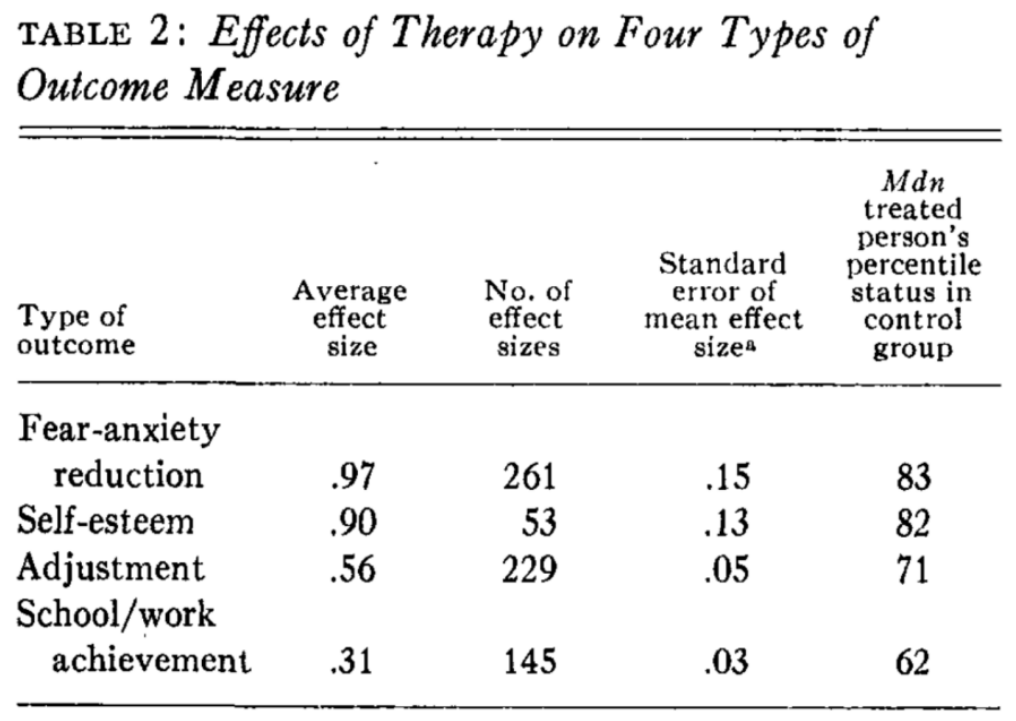
Recht große Verbesserung auf der Angstachse \((d=0{,}97)\), eher geringe Verbesserung im Schul/Arbeitsumfeld \((d=0,{31})\).
Ergebnis ist mit Vorsicht zu genießen: keine Information über die jeweils behandelten Erkrankungen; recht alte Studie, die Probleme wie Publikationsbias und Studienqualität nicht nach heutigen Maßstäben berücksichtigt.
Beispiel 1: wirkt Psychotherapie?
- Metaanalyse von Smith und Glass (1977)10
- Unterschiede zwischen Verhaltenstherapie (behavioral) und anderen Therapieformen (nonbehavioral)
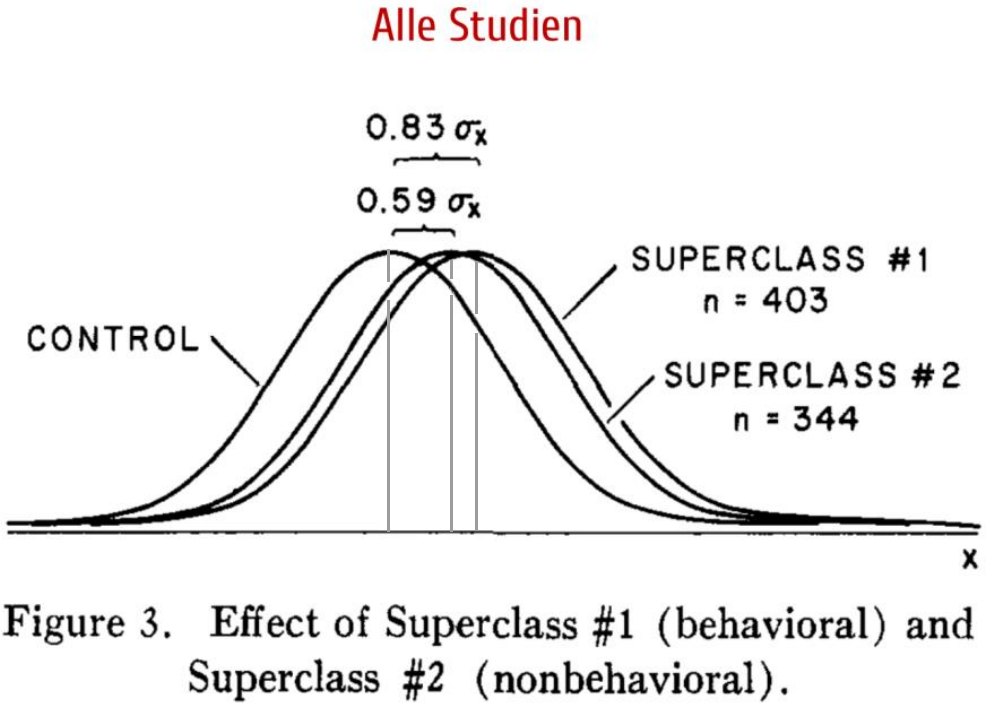
Für diese Analyse wurden die verschiedenen Therapieformen in die Superklassen “behavioral” (403 Studien) und “nonbehavioral” (344 Studien) unterteilt. Die Analyse zeigt einen Vorteil für Verhaltenstherapie an (\(d=0{,}83\) vs. \(d=0{,}59\)).
Ergebnis ist mit Vorsicht zu genießen: keine Information über die jeweils behandelten Erkrankungen; recht alte Studie, die Probleme wie Publikationsbias und Studienqualität nicht nach heutigen Maßstäben berücksichtigt.
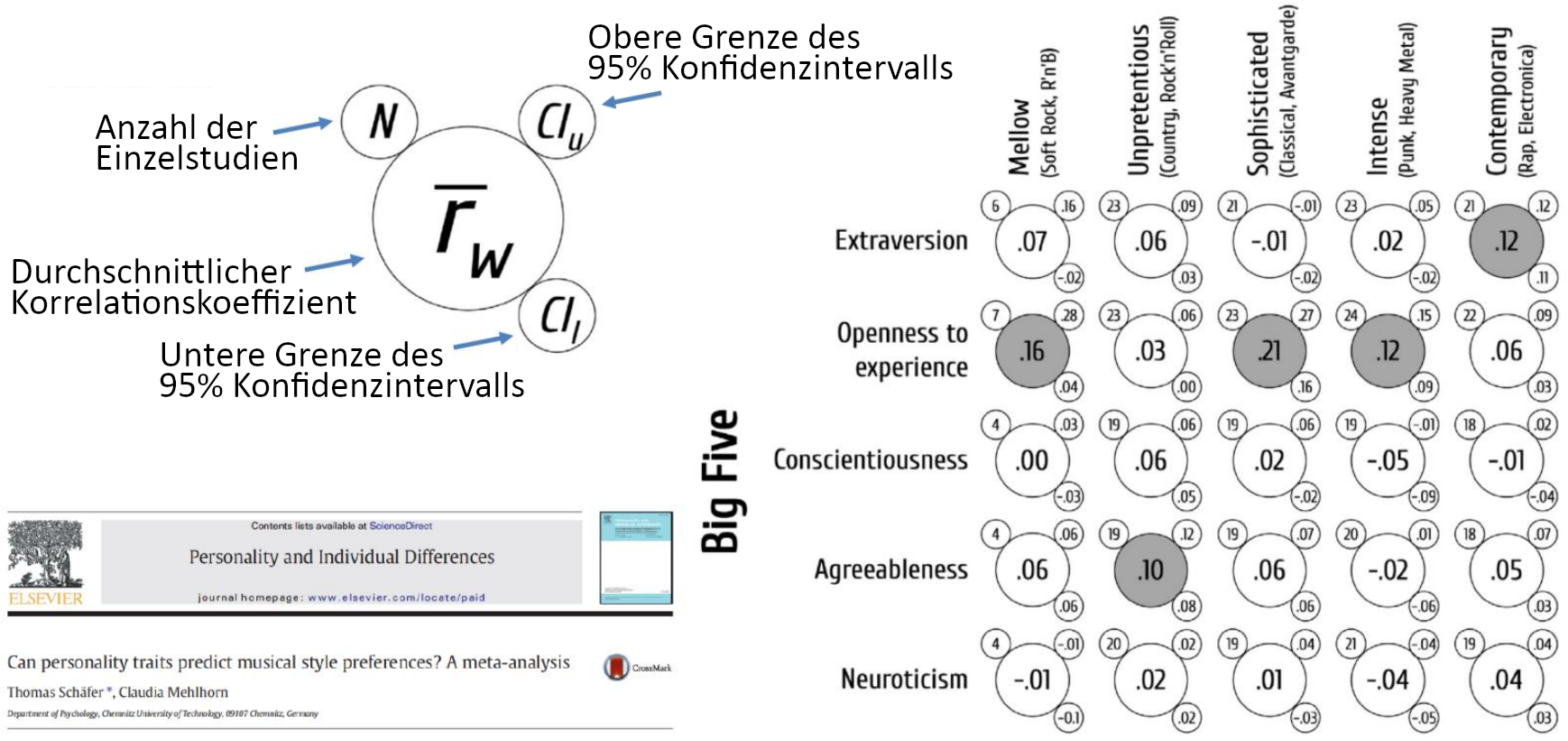
Beispiel 2: Musikpräferenzen und Persönlichkeit
- Moderne Metaanalyse von Schäfer & Mehlhorn (2017)11
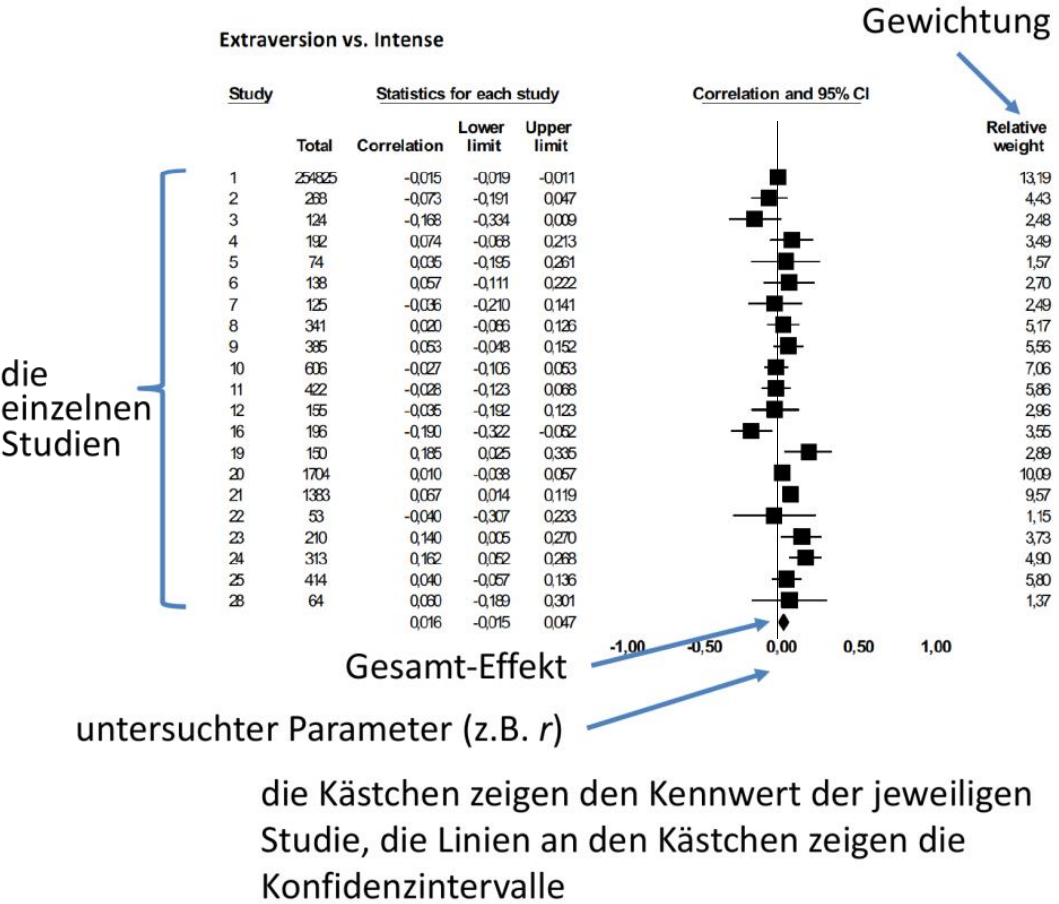
Forest-Plot
Die Ergebnisse der einbezogenen Studien sowie das Gesamtergebnis werden in einem Forest-Plot dargestellt (zeigt die Effekte und ihre Konfidenzintervalle).
- Schnelle visuelle Orientierung über gemeinsame Trends der betrachteten Studien.
- Jedes quadratische Kästchen repräsentiert die Effektstärke einzelner Studien.
- Konfidenzintervalle geben Unsicherheit der einzelnen Studien an.
- Diamant-Symbol in der letzten Reihe zeigt den gemittelten Gesamteffekt.
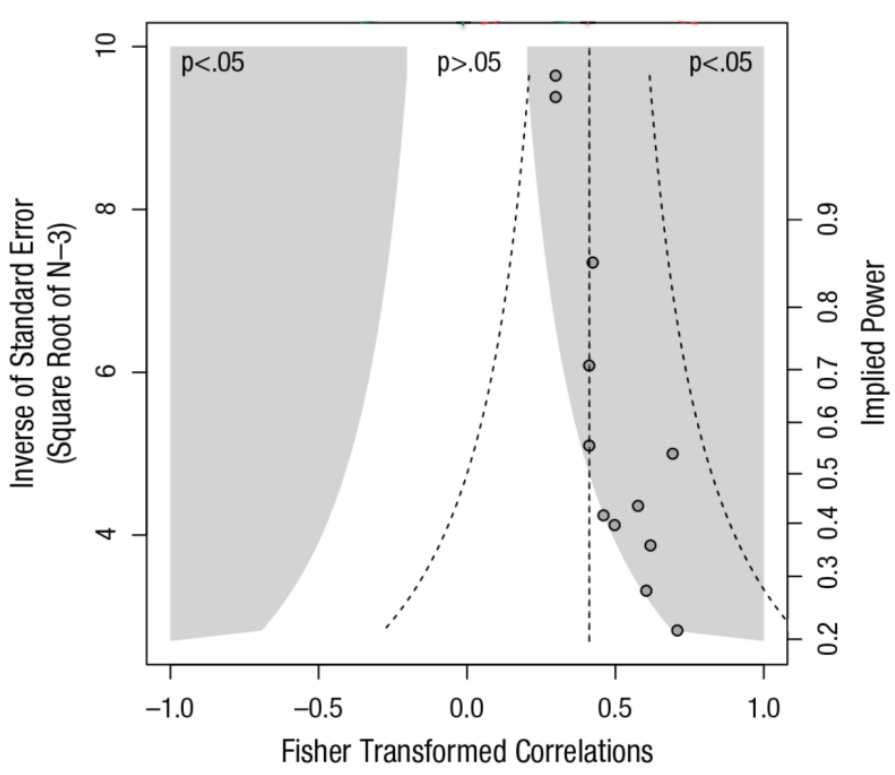
Funnel plot
Funnel Plot: visuelle Methode zur Diagnose eines Publikationsbias’
- Effekte aller Studien werden gegen ihre jeweilige Präzision abgetragen (z. B. Stichprobengröße \(n\)).
- Wenn kein Publikationsbias vorliegt, sollte ein umgekehrter Trichter (engl. funnel) entstehen, da die Varianz der Schätzungen bei größeren Stichproben systematisch kleiner werden sollte (Gesetz der großen Zahl).
- Wenn ein Publikationsbias vorliegt, wird der Funnel asymmetrisch,

Funnel plot
Funnel Plot: visuelle Methode zur Diagnose eines Publikationsbias’
- Beispiel: Meta-Analyse zum Zusammenhang von Habituationsfähigkeit im Kindesalter und späterem IQ12
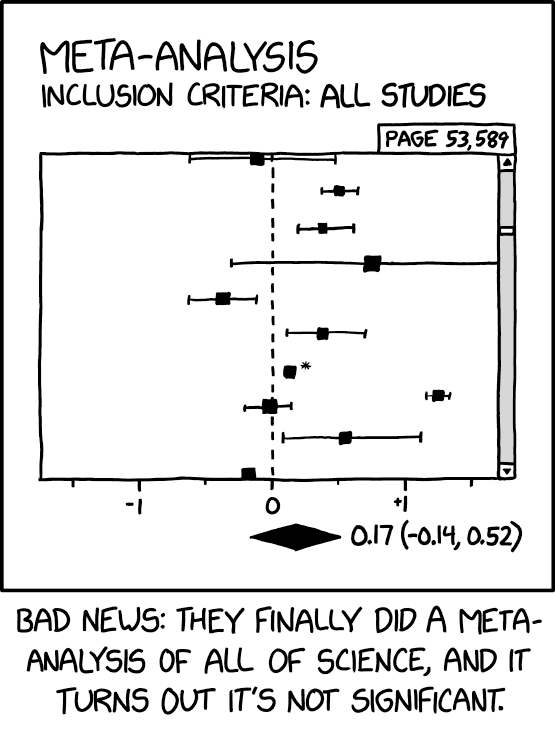
If science were a game, a dominant rule would probably be to collect results that are statistically significant. Several reviews of the psychological literature have shown that around 96% of papers involving the use of null hypothesis significance testing report significant outcomes for their main results but that the typical studies are insufficiently powerful for such a track record. We explain this paradox by showing that the use of several small underpowered samples often represents a more efficient research strategy (in terms of finding p < .05) than does the use of one larger (more powerful) sample.
Bakker et al (2012): The Rules of the Game Called Psychological Science.

- Eine Metaanalyse aggregiert standardisierte oder unstandardisierte Effekte aus verschiedenen Studien.
- Sie basiert also auf einer empirischen Stichprobenverteilung.
- Die Bestimmung des mittleren Effektes erfolgt in der Regel mit einem gewichteten Mittelwert.
- Gewichtung anhand der Präzision der einzelnen Studien (die Präzision hängt stark von der Stichprobengröße ab).
- Metaanalysen liefern bessere Schätzungen für den wahren Populationseffekt als einzelne Studien.
- Ergebnisse von Metaanalysen sind häufig durch einen Publikationsbias verzerrt, da vorrangig große/signifikante Effekte publiziert wurden – der wahre Effekt wird dann überschätzt.

![]()
Fußnoten
https://openmd.com/guide/levels-of-evidence
https://xkcd.com/2755/
Glass, G. V. (1976). Primary, Secondary, and Meta-Analysis of Research. Educational Researcher, 5(10), 3. doi:10.2307/1174772
Askie, L., & Offringa, M. (2015). Systematic reviews and meta-analysis. Seminars in Fetal and Neonatal Medicine, 20(6), 403–409. doi:10.1016/j.siny.2015.10.002
Borenstein, M. (2009). Effect sizes for continuous data. In H. Cooper, L. V. Hedges & J. C. Valentine (Eds.), The Handbook of Research Synthesis and Meta-Analysis (pp. 221-236). New York: Russell Sage Foundation.
https://stats.stackexchange.com/questions/226836/sampling-variance-for-meta-analysis-one-sample-data
Smith ML, Glass GV (1977) Meta-analysis of psychotherapy outcome studies. American Psychologist 32:752–760.
Smith ML, Glass GV (1977) Meta-analysis of psychotherapy outcome studies. American Psychologist 32:752–760.
Smith ML, Glass GV (1977) Meta-analysis of psychotherapy outcome studies. American Psychologist 32:752–760.
Smith ML, Glass GV (1977) Meta-analysis of psychotherapy outcome studies. American Psychologist 32:752–760.
Schäfer T, Mehlhorn C (2017) Can personality traits predict musical style preferences? A meta-analysis. Personality and Individual Differences 116:265–273.
Bakker M, Van Dijk A, Wicherts JM (2012) The Rules of the Game Called Psychological Science. Perspect Psychol Sci 7:543–554.